
Structured data extraction with schema validation is the process of pulling data from raw sources and confirming it conforms to a predefined schema before it enters your pipeline. Done right, it prevents type mismatches, missing fields, and malformed records from corrupting downstream analytics or AI outputs. Validation is non-negotiable in any production extraction pipeline, and as of Q2 2026, industry standards place it immediately after extraction, not as an afterthought. Tools like JSON Schema, Pydantic, Oracle's IS_VALID function, and frameworks like Struktur and Structure-D give developers the building blocks to enforce data contracts at every stage.
What are the key tools and schema validation methods?
Schema validation methods fall into two broad categories: structural and semantic. Structural validation confirms that a document matches a defined shape, such as required fields, correct types, and no unexpected keys. Semantic validation goes further and enforces business logic, such as value ranges, pattern matching, and cross-field rules.
JSON Schema and Pydantic are the two most widely used tools for structural validation in extraction pipelines. JSON Schema defines the shape of a JSON document using keywords like required, type, and additionalProperties. Pydantic, popular in Python workflows, adds runtime type enforcement and integrates naturally with LLM output parsers. Both tools catch obvious structural errors, but JSON Schema does not enforce business logic such as numeric ranges or semantic rules. That gap requires custom validator logic layered on top.

At the database layer, Oracle and MySQL both support JSON Schema validation natively. Oracle's IS_VALID and MySQL's JSON_SCHEMA_VALID return binary validity indicators and surface error details at the point of insertion. This means invalid records never reach your tables in the first place. That is a fundamentally different enforcement model than validating in application code after the fact.
| Tool | Type | Best Use Case |
|---|---|---|
| JSON Schema | Structural | Defining and enforcing document shapes |
| Pydantic | Structural + type coercion | Python LLM output parsing |
| Oracle IS_VALID | Database-layer structural | Enterprise SQL pipelines |
| MySQL JSON_SCHEMA_VALID | Database-layer structural | MySQL-based ingestion workflows |
| Struktur | AI extraction + validation | PDF, HTML, and image extraction |
| Structure-D | Validation feedback loop | Self-healing LLM extraction |
For AI-driven extraction, frameworks like Struktur and Structure-D take a schema-first approach. You define the output schema upfront, the LLM extracts data against it, and the framework validates the result. If validation fails, the error message feeds back into the next prompt. This loop closes the gap between what an LLM produces and what your pipeline actually needs.
Pro Tip: Always set additionalProperties: false in your JSON Schema. This prevents unexpected keys from slipping through and causing silent failures in downstream consumers.
How do you build automated extraction pipelines?
Automated extraction pipelines with schema validation follow a repeatable four-step pattern. Each step has a specific failure mode, and knowing those failure modes in advance is what separates a reliable pipeline from one that breaks silently.
-
Define your schema. Write a JSON Schema or Pydantic model that captures every field your downstream system expects. Include required fields, type constraints, enum values where applicable, and set
additionalPropertiesto false. Treat this schema as a contract, not a suggestion. -
Extract the data. Call your extraction layer, whether that is a regex parser, an HTML scraper, or an LLM prompt. For structured sources like APIs or well-formed HTML tables, deterministic parsing is faster and more predictable. For unstructured sources like PDFs, scanned documents, or free-text web pages, LLM-based extraction handles ambiguity better. Hybrid extraction using deterministic methods for high-structure data and LLMs for messy documents produces the most reliable enterprise results.
-
Validate the output. Run the extracted JSON through your schema validator immediately. Do not pass unvalidated data to the next stage. Capture the full error object, not just a pass/fail flag. Specific error messages like "field 'invoice_date' expected string, got null" are what make the next step possible.
-
Retry on failure. Feed the validation error back into the LLM prompt as context. Automated retry loops allow frameworks like Struktur to correct hallucinated or malformed outputs within one to two attempts. Set a retry limit of two to three attempts before routing the record to a dead-letter queue for human review.
Here is a pseudocode sketch of this loop using a Struktur-style approach:
schema = load_schema("invoice.json")
raw = fetch_document(url)
for attempt in range(MAX_RETRIES):
extracted = llm_extract(raw, schema)
result = validate(extracted, schema)
if result.valid:
return extracted
else:
raw = append_error_context(raw, result.errors)
raise ExtractionFailure(result.errors)
Self-healing pipelines treat validation as a feedback mechanism, not just a filter. The distinction matters. A filter discards bad data. A feedback mechanism fixes it. That shift in framing is what reduces manual correction work at scale.
Pro Tip: Match your extraction method to data source volatility. Use deterministic parsers for stable, structured sources like APIs and CSVs, and reserve LLM extraction for documents where structure varies between records.
What common challenges arise in schema validation?
Schema validation surfaces three categories of errors in practice: structural failures, type mismatches, and semantic violations. Each requires a different response.
Structural failures occur when required fields are missing entirely. This usually means the extraction step did not find the data, not that the data does not exist. Check your prompt or parser logic before assuming the source is incomplete.
Type mismatches are the most common error in LLM-driven extraction. An LLM might return a date as "January 5, 2026" when your schema expects "2026-01-05". JSON Schema flags this, but it does not fix it. Your retry prompt needs to include the format requirement explicitly.
Semantic violations are the hardest to catch. LLMs may hallucinate values that pass structural validation but violate business logic, such as a negative invoice total or a zip code with six digits. JSON Schema alone will not catch these. You need custom validators that enforce ranges, patterns, and cross-field rules.
Schema validation catches what your schema describes. It cannot catch what your schema fails to describe. The quality of your validation is bounded by the quality of your schema design.
Handling schema evolution is a separate challenge. When your source data adds a new field, a strict schema with additionalProperties: false will reject records that include it. The solution is to version your schemas and use optional fields for new additions until you are ready to make them required. Tools like Pydantic support field-level defaults and optional typing natively, which makes incremental schema evolution manageable without breaking existing pipelines.
For debugging, generate human-readable error messages at every validation failure. A message like "validation failed" is useless. A message like "field 'sku' failed enum constraint: received 'XYZ-99', expected one of ['XYZ-01', 'XYZ-02']" tells you exactly where to look.
How does schema validation integrate with modern data workflows?
Schema validation integrates into data workflows at two distinct points: at write time and at read time. The choice between these two paradigms has real consequences for pipeline reliability and operational overhead.
Schema-on-write enforces the contract when data enters storage. Database-layer validation using Oracle IS_VALID or MySQL JSON_SCHEMA_VALID is the clearest example. Invalid records are rejected at insertion. This keeps your data store clean but requires your schema to be stable before ingestion begins.
Schema-on-read defers validation until query time. This is common in data lake architectures where raw data is stored first and validated later. It offers flexibility during ingestion but pushes validation errors downstream, where they are harder and more expensive to fix.
| Integration Point | Approach | Pros | Cons |
|---|---|---|---|
| Database layer | Oracle IS_VALID, MySQL JSON_SCHEMA_VALID | Rejects invalid data at entry | Requires stable schema upfront |
| Application layer | Pydantic, JSON Schema validators | Flexible, language-native | Errors reach app before storage |
| AI pipeline layer | Struktur, Structure-D retry loops | Self-correcting, LLM-aware | Adds latency per retry |
| Data lake (read) | Schema-on-read with Spark or dbt | Handles schema evolution well | Errors surface late |
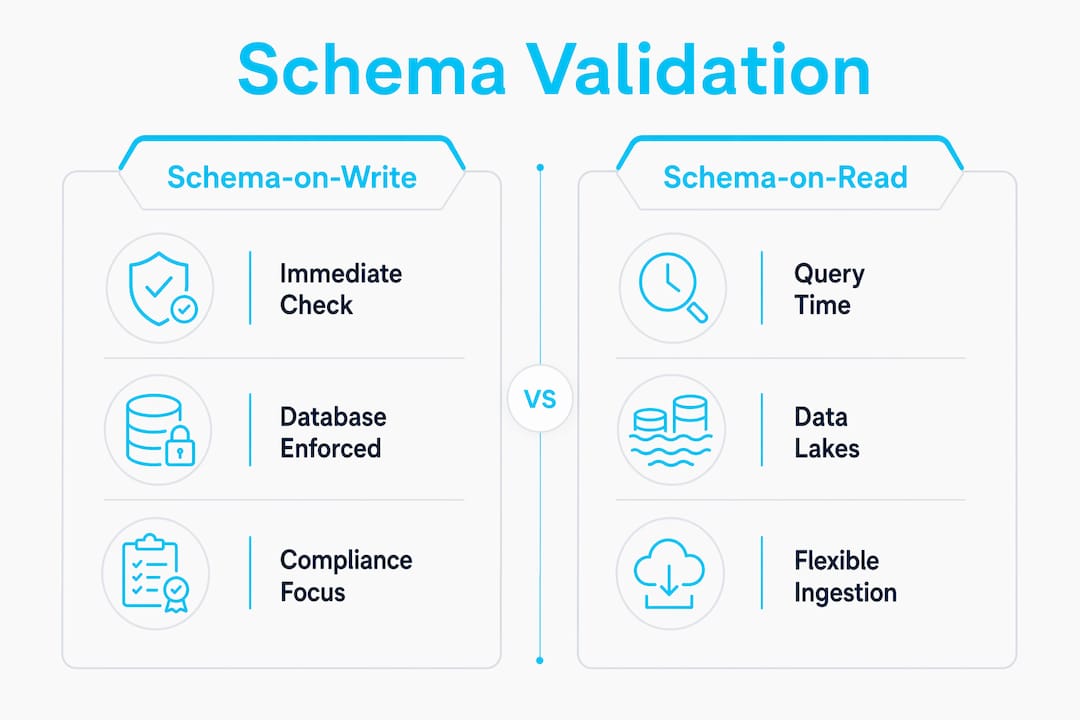
For compliance and auditability use cases, schema-on-write is the correct default. Regulated industries need a clear record that data met a defined standard at the point of ingestion. Schema-on-read makes that audit trail harder to reconstruct. If your pipeline feeds a compliance report or an AI training dataset, enforce the schema at write time and log every rejection with its full error payload.
Cloud data platforms like Snowflake and BigQuery support schema enforcement at the table level, which gives you database-layer validation without managing your own SQL functions. For AI data pipelines specifically, pairing a cloud platform's schema enforcement with an application-layer retry loop using Pydantic or Structure-D gives you two independent validation checkpoints.
Key takeaways
Reliable structured data extraction requires schema validation at every stage of the pipeline, from extraction through storage, using structural, semantic, and database-layer enforcement together.
| Point | Details |
|---|---|
| Validate immediately after extraction | Place schema validation right after extraction to catch errors before they propagate downstream. |
| Use hybrid extraction methods | Combine deterministic parsing for structured sources with LLM extraction for unstructured documents. |
| Build self-healing retry loops | Feed specific validation error messages back into LLM prompts to correct outputs within 1–2 retries. |
| Enforce semantic rules beyond JSON Schema | Add custom validators for ranges, patterns, and cross-field logic that JSON Schema cannot enforce alone. |
| Choose schema-on-write for compliance | Database-layer validation rejects invalid records at insertion, creating a clean and auditable data store. |
Why semantic validation is the part most teams skip
Most extraction pipelines I have reviewed get the structural layer right. JSON Schema is well-documented, Pydantic is easy to adopt, and database-layer validation is increasingly built into the platforms teams already use. The gap is almost always semantic validation.
The uncomfortable truth is that a pipeline can pass every structural check and still produce data that is analytically wrong. An LLM extracting financial records might return a plausible-looking revenue figure that is off by an order of magnitude. Your schema says "number." The value is a number. The validator says pass. Your analyst builds a model on garbage.
The fix is not complicated, but it requires deliberate effort. You need to encode business rules as validators, not just data shapes. That means defining acceptable ranges for numeric fields, enforcing pattern constraints on identifiers, and writing cross-field rules that catch logical contradictions. Frameworks like Structure-D make this easier by treating validation as a feedback loop rather than a gate. The error specifics become part of the correction prompt.
The teams that get this right treat their schema as a living document. They update it when new edge cases surface, version it when the source data changes, and log every validation failure as a signal about where the extraction logic needs work. That discipline is what separates a pipeline you can trust from one you have to babysit.
— Glen
Build reliable extraction pipelines with Gyrence
If you are building extraction pipelines that need to produce clean, validated, agent-ready data at scale, Gyrence is worth a close look. Gyrence is a web data API built for AI agents and data teams, with five composable primitives: Search, Traverse, Fetch, Extract, and Map. The Extract primitive accepts a schema or prompt and returns structured JSON, with typed responses for both success and failure cases so your pipeline can reason about what went wrong instead of guessing.
Gyrence names its failure modes explicitly, which means your validation layer gets real error context rather than a generic timeout or null response. Spending caps and structured failure modes mean your scraping costs stay predictable even when sources change. For teams building RAG pipelines, compliance data feeds, or AI agent workflows, that level of observability is the difference between a pipeline you ship and one you debug indefinitely.
FAQ
What is structured data extraction with schema validation?
Structured data extraction with schema validation is the process of pulling data from raw sources and verifying it conforms to a predefined schema before it enters a pipeline or database. It prevents type mismatches, missing fields, and malformed records from reaching downstream systems.
Which schema validation tools are best for LLM pipelines?
Pydantic and JSON Schema are the most widely used tools for LLM output validation in Python pipelines. Frameworks like Struktur and Structure-D extend these with automated retry loops that feed validation errors back into the LLM prompt for self-correction.
How do retry loops improve extraction accuracy?
Automated retry loops pass specific validation error messages back into the LLM as context, enabling the model to correct its output. Most frameworks resolve extraction errors within one to two retry attempts.
What is the difference between schema-on-write and schema-on-read?
Schema-on-write validates data at the point of insertion, rejecting invalid records immediately. Schema-on-read defers validation until query time, which offers flexibility but allows errors to propagate further into the pipeline before detection.
Can JSON schema enforce business logic?
JSON Schema enforces structural rules like required fields and data types, but it does not enforce business logic such as value ranges or semantic constraints. Those require custom validators layered on top of the base schema.