
Structured web data for RAG is defined as machine-readable, schema-compliant web content that retrieval-augmented generation systems use to fetch precise facts rather than infer them from free-form text. Formats like JSON-LD, semantic HTML, and cleaned Markdown give RAG pipelines explicit entity types and typed properties. This structured format reduces hallucination probability by making fact extraction deterministic rather than probabilistic. Schema.org provides the shared vocabulary that LLMs already understand well, which means structured inputs translate directly into grounded, reliable outputs. The difference between a RAG system that hallucinates product prices and one that returns exact figures almost always comes down to data structure at the source.
What is structured web data for RAG?
Structured web data for RAG refers to any web content encoded in a format that machines can parse without guessing. The three dominant formats are JSON-LD, semantic HTML, and Markdown. JSON-LD embeds entity metadata directly in a page's <script> tag, making product names, prices, authors, and dates available as typed fields. Semantic HTML uses elements like <article>, <section>, and <h1> to signal content hierarchy. Cleaned Markdown preserves that hierarchy in a format LLMs can process without stripping noise from raw HTML.
The core advantage is determinism. When a RAG system queries a JSON-LD block for a product price, it retrieves a typed value. When it queries raw paragraph text for the same fact, it runs inference. JSON-LD metadata extraction transforms RAG lookup from inference to simple data retrieval, which is the difference that matters at enterprise scale. Deadlines, prices, and compliance values cannot tolerate probabilistic answers.

Schema.org's shared vocabulary is a practical reason structured data works so well in RAG. LLMs are trained on web data that includes Schema.org markup, so they recognize entity types like Product, Person, Event, and Article without additional instruction. That recognition speeds up grounding and reduces the prompt engineering required to extract facts reliably.
What are the main types of web data used in RAG systems?
RAG data sources in 2026 fall into three categories, each with distinct tradeoffs between precision and freshness:
-
Static documents. These include product manuals, policy documents, internal wikis, and technical specifications. They change infrequently and are easy to pre-process and index. The risk is staleness. A policy document indexed six months ago may no longer reflect current rules.
-
Structured APIs with typed schema data. Product catalogs, CRM records, inventory systems, and financial databases return schema-consistent typed data on demand. Structured APIs avoid parsing noise and ambiguity, which directly improves RAG output quality. This category is the most reliable source for numeric and relational facts.
-
Dynamic live content. Pricing pages, stock levels, news feeds, and real-time dashboards fall here. This data is fresh but structurally inconsistent. A pricing page rendered by JavaScript may return different HTML on each request, making reliable extraction harder.
The practical rule is to favor structured APIs over raw web scraping whenever the data exists in both forms. A product catalog API that returns typed JSON is always more accurate than scraping the same product page for the same price. Raw scraping introduces layout changes, JavaScript rendering failures, and encoding issues that compound downstream in the retrieval pipeline.
Pro Tip: When building a RAG data inventory, tag each source by type and assign a freshness requirement. Static documents can be re-indexed weekly. Live pricing data may need hourly or real-time refresh. Mixing these on the same indexing schedule is a common source of stale retrieval.
How does structured RAG differ from unstructured RAG?
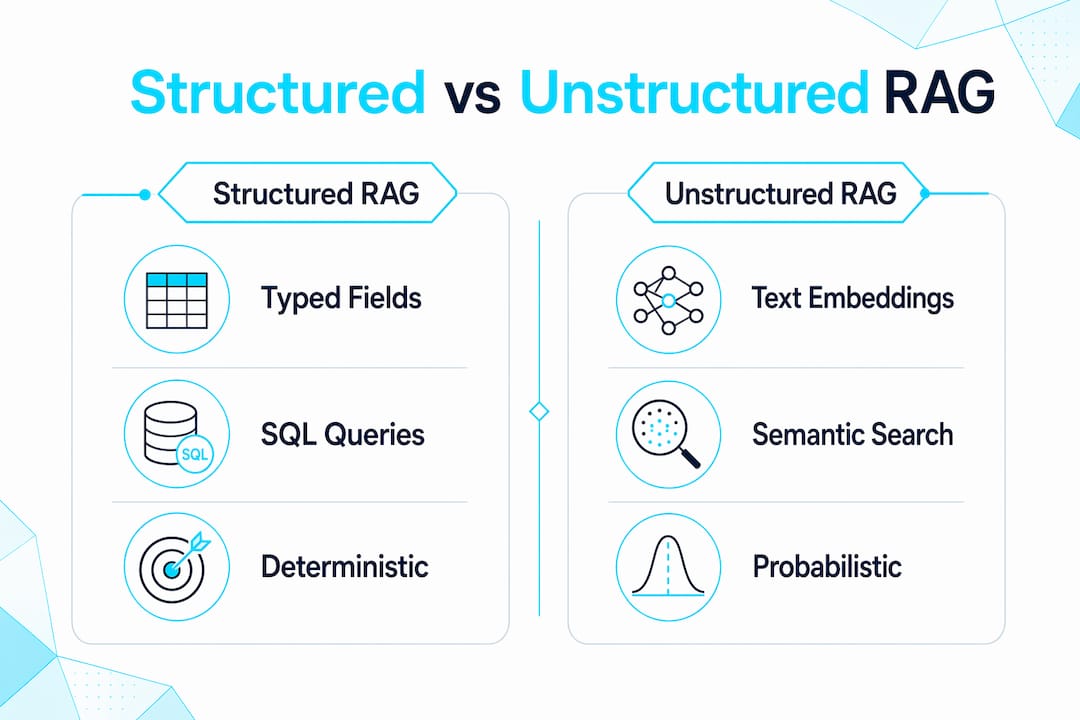
The distinction is not just technical. It changes how you design the entire retrieval layer.
| Dimension | Structured RAG | Unstructured RAG |
|---|---|---|
| Data format | Typed schema fields, SQL tables, JSON | Free-form text, PDFs, raw HTML |
| Query method | SQL filters, metadata filters, exact lookup | Vector similarity search, embeddings |
| Numeric precision | High. Returns exact values | Low. Infers values from context |
| Relational logic | Supported natively | Requires inference |
| Setup complexity | Higher. Requires schema design | Lower. Works on raw text |
| Best fit | Prices, dates, records, compliance | Concepts, summaries, open-ended Q&A |
Structured RAG translates natural language queries into structured queries such as SQL, which return precise records for LLM generation. The LLM uses those records directly rather than reading through paragraphs to find a number buried in prose. This matters most when the answer is a specific value: a deadline, a price, a regulatory threshold.
Unstructured RAG uses embedding models to find semantically similar text chunks. Embedding models excel at semantic similarity but struggle with numeric precision and relational logic. Asking an embedding-based system "What is the current price of SKU-4421?" is asking it to do something it was not designed for.
The right architecture for most production systems is hybrid. Use vector search for open-ended conceptual queries and structured filters for exact-value lookups. Neither approach alone handles the full range of queries a real application receives.
Pro Tip: Label your data at ingestion time. Tag each chunk or record with its source type (structured API, static doc, live page) and data category (numeric, relational, narrative). This metadata becomes the routing signal that tells your retrieval layer which method to use.
Best practices for chunking and processing structured web data
Processing quality determines retrieval quality. The steps below are ordered by impact.
-
Convert raw HTML to clean Markdown before indexing. Converting raw HTML to clean Markdown while preserving structure removes noise and creates semantically rich content that LLMs process more effectively. Raw HTML carries navigation menus, cookie banners, footer links, and inline styles. None of that belongs in your embedding index.
-
Use semantic chunking, not fixed-character splits. Semantic chunking using Markdown headers aligns data chunks with meaningful content boundaries, improving embedding relevance compared to fixed-length chunks. A fixed 512-token split will cut a pricing table in half or separate a section heading from its content. Semantic chunking respects the document's own structure.
-
Extract JSON-LD blocks as separate metadata records. Do not embed JSON-LD content inside a text chunk. Extract it as a structured record with typed fields. This lets your retrieval layer filter on entity type, date range, or price without running a vector search at all.
-
Preserve heading hierarchy in chunk metadata. When you split a document at an
<h2>boundary, store the heading text as a metadata field on each child chunk. This gives the retrieval layer context about where in the document a chunk came from, which improves ranking precision. -
Validate schema consistency before indexing. A product record missing a
pricefield or a date field stored as a string instead of ISO 8601 will cause silent retrieval failures. Run schema validation at ingestion, not at query time.
The payoff for this work is measurable. Clean, semantically chunked data produces embeddings that cluster correctly. Poorly processed data produces embeddings that place unrelated content in the same neighborhood, which is the mechanical cause of many retrieval failures that teams misattribute to model quality.
How to integrate structured web data into RAG pipelines
Integration is where architecture decisions become concrete. The following practices apply to production RAG systems handling structured web data.
-
Use JSON-LD fields as metadata filters during retrieval. Extracting JSON-LD blocks as metadata enables filtering and entity-specific ranking in retrieval. A query for "events in Chicago next month" should filter on
Evententity type and date range before running any vector search, not after. -
Match retrieval technique to data type. Vector search belongs on narrative content. SQL filters and metadata filters belong on typed records. Hybrid retrieval strategies combining vector search and structured query filters offer the best results, avoiding forcing all data into embedding space.
-
Use Schema.org vocabulary to define entity relationships. Schema.org's
sameAs,isPartOf, andrelatedToproperties let you build a lightweight knowledge graph on top of your indexed data. This graph becomes a second retrieval layer for relational queries that vector search cannot handle. -
Prefer APIs that return schema-consistent data. When you have a choice between scraping a page and calling an API for the same data, the API is always the better source. Schema-consistent API responses require no normalization and no layout-change monitoring.
| Data Type | Recommended Retrieval Method | Why |
|---|---|---|
| Product prices, dates | Metadata filter or SQL | Exact values, no inference needed |
| Policy documents | Vector search | Conceptual, narrative content |
| Entity records (CRM, catalog) | Structured query | Relational, typed fields |
| News and live content | Hybrid (vector + recency filter) | Semantic + freshness both matter |
| Technical documentation | Vector search with heading metadata | Conceptual with structural context |
The integration pattern that fails most often is treating all data as text. Teams ingest a product catalog as a text dump, run vector search on it, and then wonder why the system returns the wrong price. The data was structured at the source. The pipeline discarded that structure. Rebuilding it from embeddings is not possible.
Key takeaways
Structured web data is the foundation of reliable RAG. Systems built on typed, schema-consistent sources outperform those built on raw text across every accuracy metric that matters in production.
| Point | Details |
|---|---|
| Structured data enables deterministic retrieval | JSON-LD and typed APIs return exact values, eliminating inference errors for prices, dates, and records. |
| Three source types serve different needs | Static documents, structured APIs, and live content each require different indexing and freshness strategies. |
| Semantic chunking outperforms fixed splits | Chunking at Markdown or HTML heading boundaries preserves meaning and improves embedding quality. |
| Hybrid retrieval handles real query diversity | Vector search covers narrative queries; structured filters handle exact-value lookups. Use both. |
| Schema.org vocabulary accelerates grounding | LLMs already recognize Schema.org entity types, reducing prompt engineering and improving factual accuracy. |
Why structured data is RAG infrastructure, not an SEO tactic
Most teams I see treat structured data as something the SEO team owns. That framing is wrong, and it costs them months of debugging retrieval failures they cannot explain.
Structured data is core RAG infrastructure, not an optional layer. When your retrieval system relies on inference from messy, unstructured pages, you get unstable outputs. The model guesses. Sometimes it guesses correctly. Often it does not. The failure mode is invisible until a user catches a wrong price or a hallucinated deadline in a compliance context.
The teams that build reliable RAG systems in 2026 treat every data source as a schema design problem. Before they write a single line of retrieval code, they ask: what entity types does this source contain, what fields are typed, and what fields are free text? That question determines the entire architecture.
The common pitfall I see is over-reliance on embedding quality to compensate for poor data structure. Better embedding models do not fix a product catalog that was ingested as unstructured text. The structure was there at the source. The pipeline threw it away. No model recovers that.
Clean, typed, schema-consistent data is the one input that scales without diminishing returns. Better models help. Better prompts help. But neither substitutes for data that was structured before it entered the pipeline.
— Glen
Build your RAG pipeline on clean, structured web data
If you are building a RAG pipeline and need web data that arrives already structured, Gyrence is built for exactly that workflow. Gyrence's five API primitives (Search, Traverse, Fetch, Extract, and Map) give your pipeline typed, agent-ready data at every step. The Extract primitive returns structured JSON from any page using a prompt or schema you define. The Fetch primitive delivers clean Markdown with heading hierarchy preserved, ready for semantic chunking. Every call returns a typed, discriminated-union response including failure cases, so your pipeline handles errors without silent data loss.
Gyrence includes spending caps and bundled LLM extraction so your data ingestion costs stay predictable. Explore the full API at gyrence.com.
FAQ
What is structured web data for RAG?
Structured web data for RAG is machine-readable, schema-compliant web content in formats like JSON-LD, semantic HTML, or Markdown that retrieval-augmented generation systems use to fetch precise facts. It enables deterministic retrieval instead of probabilistic inference from free-form text.
What are the main types of structured web data in RAG?
The three main types are static documents (manuals, policies), structured APIs with typed schema data (product catalogs, CRM records), and dynamic live content (pricing pages, stock feeds). Structured APIs are preferred for numeric and relational accuracy.
Why does structured data reduce hallucinations in RAG?
Structured data provides typed, explicit field values that the retrieval layer returns directly to the LLM. The model reads a fact rather than inferring it from surrounding text, which eliminates the inference step where hallucinations originate.
What is semantic chunking and why does it matter?
Semantic chunking splits documents at logical boundaries like Markdown headers or HTML section tags rather than at fixed character or token counts. This preserves meaning within each chunk and produces higher-quality embeddings that retrieve more relevant content.
When should i use hybrid retrieval in a RAG system?
Use hybrid retrieval when your data includes both narrative content and typed records. Vector search handles conceptual queries on narrative text; structured filters handle exact-value lookups on typed fields. Forcing all data into embedding space degrades precision on numeric and relational queries.