
A search API for research is a programmatic interface that lets you query a search engine or database and receive structured data back, typically as JSON, without touching a browser or parsing raw HTML. The industry term is "web search API," though researchers often call it a "research API" or "API for data search" depending on the domain. Tools like Google Custom Search JSON API, SerpApi, and OpenAIRE Search API all follow this model. Each call returns fields like URL, title, snippet, published date, and relevance score, giving you machine-ready data from the first response. For researchers and data analysts, that means scalable, repeatable data collection without the fragility of manual scraping.
What is a search API for research, exactly?
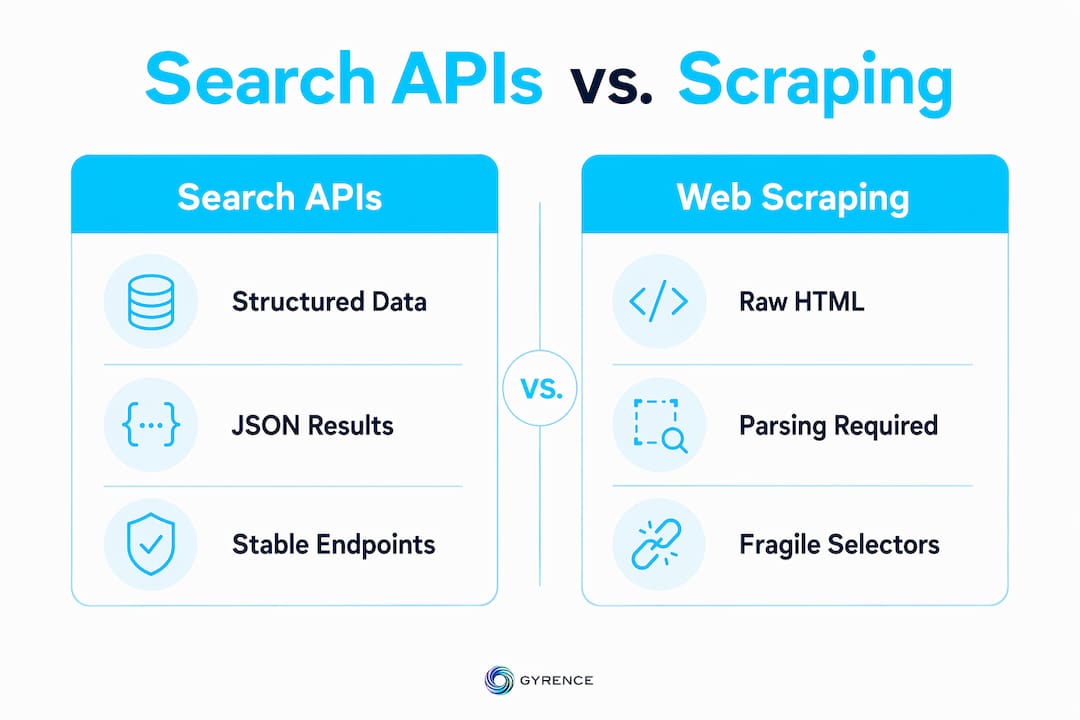
A search API is a programmatic interface enabling applications to query web indexes and receive structured JSON results with fields like URL, title, snippet, published date, and relevance score. That definition matters because it separates search APIs from general-purpose scrapers. You are not fetching a page and parsing it. You are calling an endpoint, passing query parameters, and receiving clean, typed data.
The distinction has real consequences for research workflows. Manual scraping requires you to handle HTML structure changes, CAPTCHAs, and JavaScript rendering. A search API offloads all of that to the provider. Your pipeline receives consistent output regardless of what the underlying search engine changes on its end.

Domain-specific research APIs follow the same model. Elsevier's API suite, for example, allows programmatic retrieval from scientific databases in XML and JSON formats, supporting pharmaceutical research automation with access to safety, efficacy, and pharmacokinetic data. The Google Custom Search JSON API requires an API key, supports programmable search engines, and returns metadata compliant with OpenSearch specification. These are not experimental tools. They are production-grade interfaces used in academic, commercial, and AI research pipelines.
How does a search API work and what data does it return?
Every search API call follows the same basic pattern: you send an HTTP request with a query string and optional parameters, and the API returns a structured response. Common parameters include q (query text), location, language, num (results count), start (pagination offset), and date filters. The response is almost always JSON.
Here is what a typical search API response contains:
| Field | Description | Research Use |
|---|---|---|
url | Full URL of the result | Source tracking, deduplication |
title | Page title | Topic classification |
snippet | Short text excerpt | Quick relevance screening |
published_date | Publication timestamp | Temporal filtering |
relevance_score | Provider-assigned rank signal | Quality filtering |
source_domain | Root domain of the result | Source credibility scoring |
The relevance score field is the one most researchers ignore. It is not just a rank position. It reflects the provider's confidence that the result matches your query. Filtering on this field before passing results to downstream analysis cuts noise significantly.
Contrast this with manual web scraping. Scraping requires you to fetch raw HTML, identify the correct CSS selectors or XPath expressions, handle pagination logic, and rebuild the data structure yourself. Any layout change on the target site breaks your parser. A search API returns the same schema on every call, regardless of what the source pages look like.
Pro Tip: Never assume an HTTP 200 response means your data is good. Check the relevance_score and result count on every call. A response with ten low-score results is a silent failure, not a success.
Search apis vs. traditional web scraping: which is better for research?
The honest answer is that search APIs win on reliability and maintenance, while scraping wins on flexibility. For most research workflows, reliability matters more.
Here is where search APIs have a clear structural advantage:
- Infrastructure maintenance. Search APIs handle layout changes, CAPTCHAs, and proxy rotation on the provider's side. Your pipeline does not break when a search engine updates its frontend.
- Structured output. You receive typed JSON fields, not raw HTML. That eliminates a full preprocessing stage from your workflow.
- Metadata access. Relevance scores, published dates, and source domains come pre-extracted. Scraping requires you to infer or calculate these yourself.
- Rate limit transparency. APIs publish their rate limits and return structured errors when you exceed them. Scrapers fail silently or get blocked without warning.
- Maintenance burden shift. Search APIs shift the maintenance burden from your team to the provider, freeing researchers to focus on analysis rather than infrastructure.
The tradeoff is coverage and control. A search API returns what the provider's index contains. If you need data from a site that is not indexed, or you need the full page content rather than a snippet, you will need to combine a search API with a fetch or extraction layer.
Pro Tip: Monitor your API response quality over time, not just at launch. Silent degradation occurs when APIs return HTTP 200 but result quality drops due to anti-bot measures or index changes. Build a quality check into your pipeline that flags responses with low relevance scores or fewer results than expected.
How do ai-enhanced search apis improve research accuracy?
Traditional search APIs return document-level results. AI-first search APIs go further. They surface atomic spans of information rather than entire documents, which is a fundamentally different unit of retrieval.
This distinction matters most when you are feeding search results into a language model. Passing a full document to an LLM introduces noise. The model must identify the relevant passage within the document, and it often gets that wrong. Passing an atomic chunk, a paragraph or sentence that directly answers the query, gives the model a much cleaner input.
| Feature | Traditional Search API | AI-Enhanced Search API |
|---|---|---|
| Result granularity | Full document or page | Sub-document chunks or spans |
| Retrieval model | Lexical (keyword matching) | Hybrid: lexical + semantic |
| Relevance signal | Rank position | Scored relevance per chunk |
| Hallucination risk | Higher (noisy context) | Lower (atomic grounding) |
| Latency | Lower | Higher (multi-stage ranking) |
Perplexity AI's research architecture demonstrates this approach. Their system uses hybrid retrieval models combining lexical and semantic search, with multiple ranking stages that progressively refine results under tight latency constraints. The result is higher recall and precision than either method alone.
The practical implication for researchers is significant. Search results split into chunks before ingestion into AI models significantly improve factual grounding and reduce hallucinations. If you are building a retrieval-augmented generation (RAG) pipeline or using an LLM to synthesize research findings, the granularity of your search API output directly affects the accuracy of your outputs. This is the principle behind context engineering: structuring inputs to models at the right level of specificity, not just passing raw documents and hoping for the best.
Practical applications and implementation tips for researchers
Search APIs appear in research workflows across multiple domains. The use cases cluster into three categories.
Literature and source discovery. Academic researchers use APIs like OpenAIRE and Elsevier to programmatically search publication databases, filter by date or journal, and pull metadata into citation management systems. This replaces hours of manual database browsing with a single script.
Market and competitive analysis. Researchers use search API data to discover product pages, pricing, and feature comparisons without manual browsing. A single API call with a structured query returns dozens of competitor pages with titles, URLs, and snippets already extracted.
AI training data and RAG ingestion. Data teams use search APIs as the first stage in a structured web data pipeline, feeding results into extraction and chunking layers before LLM ingestion.
Implementation follows a consistent pattern regardless of use case:
- Authenticate with an API key (store it in an environment variable, never hardcode it).
- Build your query with explicit parameters: language, date range, result count, and any domain filters.
- Parse the JSON response and validate required fields before processing.
- Implement exponential backoff for rate limit errors (HTTP 429).
- Log relevance scores and result counts per call to detect quality degradation over time.
On the legal and ethical side, check the terms of service for any API you use in research. Most commercial search APIs prohibit storing results beyond a defined window or using them to train models without a separate license. The Gyrence terms of use page is one example of how providers document these boundaries explicitly. Read the equivalent document for every API in your stack.
Pro Tip: Use a web data API evaluation checklist before committing to any provider. Evaluate rate limits, response schema stability, failure mode documentation, and pricing structure. Providers that do not document their failure modes will cost you debugging time later.
Recommended API providers for research use cases:
- Google Custom Search JSON API: General web search with OpenSearch compliance, good for broad topic discovery.
- SerpApi: Aggregates results from multiple search engines with consistent schema output.
- OpenAIRE Search API: Specialized for academic literature, open access publications.
- Elsevier APIs: Domain-specific for scientific and pharmaceutical research.
- Gyrence Search primitive: Designed for AI agents and data teams, returns typed discriminated-union responses including structured failure cases.
Key takeaways
A search API for research delivers structured, machine-ready data from web indexes, and the quality of that data directly determines the accuracy of any AI or analysis layer built on top of it.
| Point | Details |
|---|---|
| Search API definition | A programmatic interface returning typed JSON fields like URL, title, snippet, and relevance score. |
| API vs. scraping | APIs handle infrastructure changes and return consistent schemas; scrapers break on layout updates. |
| AI-enhanced retrieval | Atomic chunk results reduce LLM hallucinations more than full-document ingestion. |
| Silent degradation risk | HTTP 200 does not guarantee data quality; monitor relevance scores on every call. |
| Implementation priority | Validate response fields, log quality metrics, and read provider terms before production use. |
What i have learned using search apis in real research workflows
The biggest mistake I see researchers make is treating a search API as a black box that either works or does not. That framing misses the most important failure mode: the API works, returns 200, and gives you garbage data. Relevance scores drift. Index coverage shifts. Anti-bot measures kick in and the provider does not tell you. Your pipeline keeps running and your dataset quietly degrades.
The second mistake is ignoring the granularity question entirely. Most researchers pull full-page snippets and pass them directly to an LLM or a classifier. That works until it does not. When your model starts producing inconsistent outputs, the first thing to check is whether your context inputs are too coarse. Atomic chunks are not a theoretical nicety. They are the difference between a model that grounds its answers in your data and one that fills gaps with plausible-sounding fabrications.
The third thing I would push back on is the assumption that a general-purpose web search API is always the right tool. For academic literature, domain-specific APIs like Elsevier or OpenAIRE return metadata that general search APIs simply do not carry: DOIs, citation counts, journal names, author affiliations. Using the right API for the domain saves you a significant amount of post-processing work.
The researchers who get the most out of search APIs are the ones who treat the response schema as a first-class part of their data model, not an afterthought. Know every field. Know what a missing field means. Know what a low relevance score implies about your query. That discipline separates a reliable research pipeline from one that produces results you cannot trust.
— Glen
How Gyrence handles web data for research and AI pipelines
Researchers who need more than search snippets often hit a wall: the API returns a URL, but the actual content requires a separate fetch, clean, and extract step. Gyrence is built for exactly that workflow.
Gyrence provides five composable primitives: Search, Traverse, Fetch, Extract, and Map. Each call returns a typed, discriminated-union response that includes structured failure cases, so your pipeline knows why a call failed, not just that it did. Spending caps and predictable pricing mean your data budget does not surprise you mid-project. For teams building RAG pipelines or AI-assisted research workflows, Gyrence's web data infrastructure connects search results directly to structured extraction without stitching together multiple vendors. Start at gyrence.com to see the full API documentation and pricing structure.
FAQ
What is a search results API?
A search results API is a programmatic endpoint that returns structured data from a search engine query, including fields like URL, title, snippet, and relevance score, in JSON or XML format. It eliminates the need to parse raw HTML from search engine pages.
How do search apis differ from web scrapers?
Search APIs return pre-structured data from a provider's index, while scrapers fetch and parse raw HTML from individual pages. APIs handle infrastructure challenges like CAPTCHAs and layout changes; scrapers require ongoing maintenance when page structures change.
What are the main research API examples?
Google Custom Search JSON API, SerpApi, OpenAIRE, and Elsevier's API suite are widely used research APIs. Each targets a different domain: general web search, multi-engine aggregation, academic literature, and scientific databases respectively.
Why do AI research pipelines need atomic chunk results?
Feeding full documents into language models introduces noise and increases hallucination risk. Sub-document atomic chunks improve factual grounding by giving the model only the specific passage relevant to the query.
What is silent degradation in a search API?
Silent degradation occurs when an API returns an HTTP 200 success status but the result quality has dropped due to anti-bot measures or index changes. Monitoring relevance scores and result counts on every call is the only reliable way to detect it.